

音声認識とは?
「音声認識」とは、人間の声などをコンピューターに認識させること。音声をテキストに変換したり(Speech to Textとも言われる)、音声の特徴をとらえて、話している人を識別する機能を指します。(参照:デジタル大辞泉「音声認識」)
「OK Google!明日の天気は?」や「Hey Siri 今何時?」など、スマートフォンやスマートスピーカーに話しかける音声検索も、この音声認識によって、音声がテキストに変換され、検索に反映されています。
私たちの生活をより便利にしてくれる音声認識。
今回は、その歴史と技術についてご紹介していきます。
音声合成、感情分析、自動翻訳、などボイステックのワードを簡単に抑えたい方は、ぜひこちらの記事もご覧ください。
音声認識の歴史
実は今から70年ほど前には音声認識の研究は始まっていました。
10年ごとに区切り、その歴史を追っていきましょう。
1950年代 音声認識の研究がスタート
1950年代は、まだインターネットもなく、テレビもほとんど白黒だった時代です。日本では冷蔵庫・洗濯機・白黒テレビが「三種の神器」として憧れられていた時期でした。
そんな頃に、人間の発する声や声道の研究が行われていました。音声の特徴を分析して、数値化するようになります。
例えば、「あ」と発する時の様子をX線で撮影し、声道がどう変化するのか構造を調べて数値化。その数値に従って音を合成すれば音声合成になり、逆に、発した声がどの数値に近いかを調べれば、音声認識になるという構想のもと、こういった研究が行われていました。
そしてアメリカのベル研究所が、「Audery(オードリー)」という音声認識システムを発表。「Audery」は1〜9までの音声を認識することができるものでした。
このベル研究所は、電話の発明者グラハム・ベルが設立した会社が前身となっており、電気通信の研究を行っていました。(参考:ベル研究所)
1960年代 世界初の音声認識計算機が誕生
1960年代、日本ではカラーテレビ・クーラー・自動車が「新・三種の神器」と呼ばれていた頃です。
アメリカでは1961年、コンピューター関連企業のIBMが、世界初の音声認識計算機「Shoebox(シューボックス)」を発表。
0〜9までの数字や、プラス、マイナスを含む16単語を認識でき、マイクでShoeboxに話しかけて声で計算を行うことができました。
1962年、ほぼ同じ時期に、日本でも京都大学が音声タイプライターを開発。単語ではなく、「あ・い・う」という単音節を認識するという音声認識のシステムでした。
1970〜80年代 Siriの原型となる技術が生まれる
1970年代、日本は高度経済成長期と言われる時代でした。この頃、アメリカではSiriの原型となる技術が生まれます。軍用の機関で音声認識の開発が進んでおり、まだ私たちにとって身近な技術ではありませんでした。
1970年代は大々的なプロダクトは発表されていませんが研究は続いていました。
例えば、「あ」という音は何Hzと何Hzの音が強いという特徴がある、「い」という音は〜という具合に”周波数特性”の分析が進み、人間の音声をより簡単な数式モデルで表せるようになりました。
そして、この頃DARPA(国防高等研究計画局)が立ち上げた「CALOプロジェクト」の研究が、現在のSiriの原型となっています。
この研究に参加していたSRIインターナショナルがSiriの技術を生み出し、現在の音声認識や人工知能の研究にも大きな影響を与えています。(参考:Siri誕生の逸話–開花した“強い人工知能”競争の行方)
ちなみに、DARPAは軍隊のための技術の研究を行うアメリカ国防総省の機関であり、Siriの他にも、インターネットやGPSの原型も開発しています。(参考:国防高等研究計画局)
1990年代 音声認識を使ったゲームやカーナビが誕生
そして1990年代、日本でも研究が進み、カーナビやテレビゲームといった私たちの身近な製品にも音声認識が使われるようになります。
1993年「SANYO EXCEDIO NV-1V」
SANYOから、音声認識機能がついたカーナビが発売されました。
1998年「ピカチュウげんきでちゅう」

(出典:「ピカチュウげんきでちゅう」公式サイトより)
任天堂が、NINTENDO64のゲームソフト「ピカチュウげんきでちゅう」を発売。マイクを使ってピカチュウに話しかけると、音声が認識され、ピカチュウとコミュニケーションができるゲームでした。(参考:ピカチュウげんきでちゅう)
1999年「シーマン」
セガから、ドリームキャストのゲームソフト「シーマン ~禁断のペット~」が発売。マイクに向かって呼びかけると、シーマンが近づいたり返事をしたり、音声認識による会話ができるゲームでした。
大ヒットしたこのゲームですが、現在はその経験と知見のもと「シーマン人工知能研究所(SAIL)」という企業が、日本語の会話エンジンの研究・開発に取り組んでいます。
2010年代 音声認識の精度も向上!

2000年代は、研究が進み音声認識の手法がアップデートされていきます。
そして2010年代には、AIの急速な発展により音声認識の精度も格段に向上しました。
2011年、Appleが音声アシスタント「Siri」を発表。
iOS5、当時のiPhone 4Sに初めて搭載されました。
2012年、NTTドコモが「しゃべってコンシェル」を発表。
知りたいことをスマートフォンに話しかけると、検索ができたりアプリを操作できるものでした。(参考:音声エージェント機能「しゃべってコンシェル」の提供開始)
2016年、Googleが音声認識APIの「Google Cloud Speech API」を発表。
このAPIを利用すれば、開発者が音声認識を使ったアプリやサービスを開発できるようになりました。
音声認識の仕組み

ここまでは、音声認識がどのように発展してきたのか、その歴史を紹介してきました。
ここからは、そもそも「音声をどう認識しているのか?」という技術について、簡単に紹介していきます。
まず、基本的な音声認識に「パターンマッチング」というものがあります。
これは、人間が発した音声が、「あ」なのか「い」なのか、元々用意していた音声のデータベース上から探し出して、その音声がどういったものなのか認識するという手法です。
初めは数字のみの認識でしたが、次第に単語が認識できるようになり、扱える単語の数も増えていきます。また、私たちが話している文章も、分解すれば一つ一つの単語です。
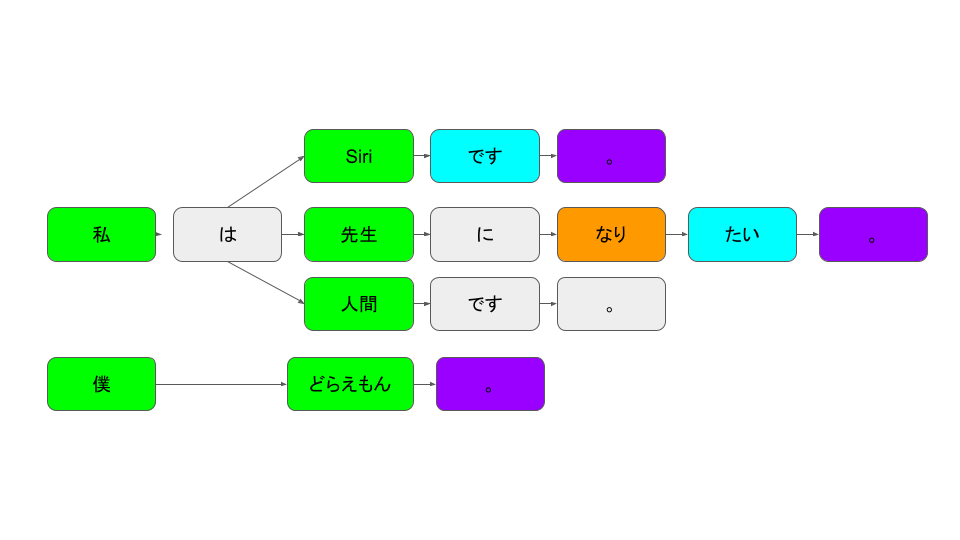
「私」のあとは「は」(助詞)がくる、その後には名詞がくる、といったように文法を導入することで、より高速に、正確に認識ができるようになっていきました。
その後、ディープラーニング(機械が自動的に大量のデータから特徴を抽出して、学習すること)の発展により、音声認識の技術も飛躍的に向上。様々な製品に音声認識が活用され、スマートスピーカーやスマートフォン、家電に話しかけて操作をする、という行動が当たり前になりました。
Voicy×音声認識の未来 あなたの好みの”声”で放送が選べるかも?
私たちVoicyも、「音声×テクノロジーでワクワクする社会をつくる」を掲げた、音声の会社です。ここからは少し、Voicyが音声認識を使ってどのようなことができるか、未来のお話をさせていただきます。
ボイスメディアVoicyは、国内最大の音声メディアプラットフォームです。2016年からサービスを開始、多くのパーソナリティが放送をしてきたので、膨大な数の音声データがあります。
例えばですが、Voicyで音声認識を活用すると、検索機能をもっと向上させることができるかもしれません。
具体的には、Voicyで話された音声を自動で書き起こしし、テキストデータ化します。リスナーは「英語」や「ドラマ」など聴きたいワードで検索すると、そのテキストデータから検索されて、よりニーズに合った放送と出会いやすくなります。
また、パーソナリティの声の音質を分析すれば、「ダンディーな低い声が聴きたいあなたへ」「透き通った声が聴きたいあなたへ」といったように、聴きたい声の特徴に合わせて、放送を提案できる機能がつくれるかもしれません。
Voicyとボイステックの未来をつくりませんか?
Voicyは、音声技術を使って、未来の社会を担う新しい事業をつくっていきます。
音声で何か面白いことをしたい!音声コンテンツを制作してみたい!と考えている方、ぜひVoicyと一緒に音声の世界をつくりませんか?
お気軽にお問い合わせください。
Voice Contents Studio
音声メディアの運営を通して獲得したノウハウやテクノロジーを活かして、従来型のPR・マーケティングとは異なる、企業の想いを込めた音声発信をプロデュースします。
声のオウンドメディアVoicy Biz
VoicyBizは、企業が本音や世界観を深く届ける、声のオウンドメディアです。ブランドとしての想いや価値観を、声で発信してみませんか?


